Building a file server with FreeBSD, ZFS and a lot of disks
Table of Contents
This is a story of how I built a Storage server based on FreeBSD and ZFS to replace aging NetApp and Isilon storage servers that were serving HPC data over NFS.
The need #
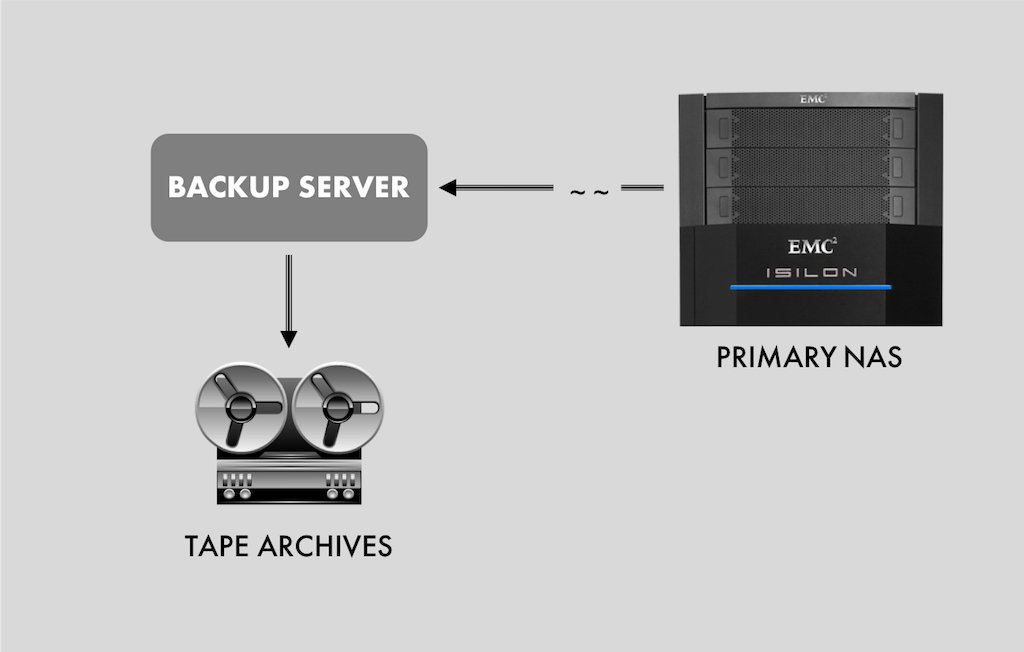
At work, we run a compute cluster that uses an Isilon cluster as primary NAS storage. Excluding snapshots, we have about 200TB of research data, some of them in compressed formats, and others not. We needed an offsite backup file server that would constantly mirror our primary NAS and serve as a quick recovery source in case of a data loss in the the primary NAS. This offsite file server would be passive - will never face the wrath of the primary cluster workload.
In addition to the role of a passive backup server, this solution would take on some passive report generation workloads as an ideal way of offloading some work from the primary NAS. The passive work is read-only.
The backup server would keep snapshots in a best effort basis dating back to 10 years. However, this data on this backup server would be archived to tapes periodically.
Snapshots != Backups.
A simple guidance of priorities:
Data integrity > Cost of solution > Storage capacity > Performance.
Why not enterprise NAS? NetApp FAS or EMC Isilon or the like? #
We decided that enterprise grade NAS like NetAPP FAS or EMC Isilon are prohibitively expensive and an overkill for our needs.
An opensource & cheaper alternative to enterprise grade filesystem with the level of durability we expect turned up to be ZFS. We’re already spoilt from using snapshots by a clever Copy-on-Write Filesystem(WAFL) by NetApp. ZFS providing snapshots in almost identical way was a big influence in the choice. This is also why we did not consider just a CentOS box with the default XFS filesystem.
FreeBSD vs Debian for ZFS #
This is a backup server, a long-term solution. Stability and reliability are key requirements. ZFS on Linux may be popular at this time, but there is a lot of churn around its development, which means there is a higher probability of bugs like this to occur. We’re not looking for cutting edge features here. Perhaps, Linux would be considered in the future.

We already utilize FreeBSD and OpenBSD for infrastructure services and we have nothing but praises for the stability that the BSDs have provided us. We’d gladly use FreeBSD and OpenBSD wherever possible.
Okay, ZFS, but why not FreeNAS? #
IMHO, FreeNAS provides a integrated GUI management tool over FreeBSD for a novice user to setup and configure FreeBSD, ZFS, Jails and many other features. But, this user facing abstraction adds an extra layer of complexity to maintain that is just not worth it in simpler use cases like ours. For someone that appreciates the commandline interface, and understands FreeBSD enough to administer it, plain FreeBSD + ZFS is simpler and more robust than FreeNAS.
Specifications #

- Lenovo SR630 Rackserver
- 2 X Intel Xeon silver 4110 CPUs
- 768 GB of DDR4 ECC 2666 MHz RAM
- 4 port SAS card configured in passthrough mode(JBOD)
- Intel network card with 10 Gb SFP+ ports
- 128GB M.2 SSD for use as boot drive
- 2 X HGST 4U60 JBOD
- 120(2 X 60) X 10TB SAS disks
FreeBSD #
Both the JBODs are connected to the rack server with dual SAS cables for connection redundancy. The rack server would see 120 disks attached to it that it can own. The rack server was in turn connected to a switch with a high bandwidth link to the primary storage server. Once the physical setup was complete, it was time to install FreeBSD. Simple vanilla installation of FreeBSD 11.2 based on a USB install media. Nothing out of the ordinary.
Run updates and install basic tools:
> freebsd-update fetch
> freebsd-update install
> pkg upgrade
> pkg install nano htop zfsnap screen rsync
> echo 'sshd_enable="YES"' >> /etc/rc.conf
> service sshd start
ZFS #
The Z File System, is actually more than just a filesystem. It serves as a volume manager + filesystem. It is almost always better to provide raw disks to ZFS instead of building RAID to make multiple disks appear as one. In our setup we’d like for the 120 disks from JBODs to be owned by ZFS.
Enable ZFS
> echo 'zfs_enable="YES"' >> /etc/rc.conf
> service zfs start
Basic ZFS terminology #
A storage pool(zpool) is the most basic building block of ZFS. A pool is made up of one or more vdevs, the underlying devices that store the data. A zpool is then used to create one or more file systems (datasets). A vdev is usually a group of disks(RAID).ZFS spreads data across the vdevs to increase performance and maximize usable space.
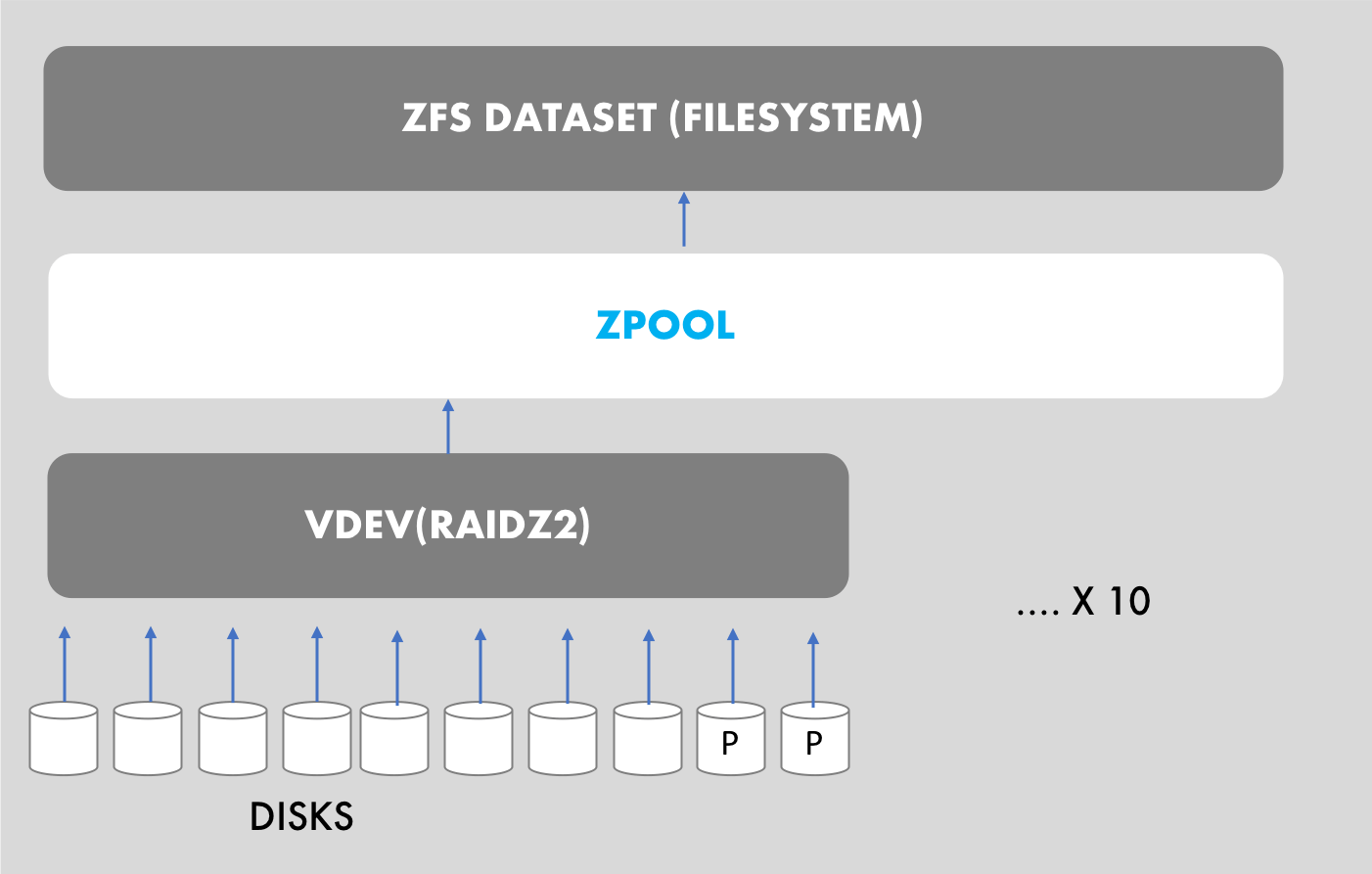
When building out a ZFS based filesystem, one needs to carefully plan the number and type of vdevs, number of disks in each vdev etc according to their specific needs. Simple fact is that the more vdevs you add, the more ZFS spreads the writes thereby improving performance. However, each vdev(equivalent of a RAID group in NetApp world) dedicates some disk space for parity data to provide the recoverability that we desire from ZFS. This simply translates to another fact that using more number of vdevs will result in reduced usable storage capacity.
Just to be clear, the parity and redundancy are only within a vdev. if the system loses a disk in a vdev, it holds up, and resilvers a spare disk or awaits a new disk, but still servicing user work. But, if the system loses a vdev, the entire zpool is bust. Keep this in mind when you plan for redundancy.
Given that I have 120 disks at my disposal, I needed to choose between the following options on my drawing board. I decided to go with RAIDZ2 so that the system can tolerate simultaneous failure of 2 disks per vdev. Considering that I have hot spares, anything beyond RAIDZ2 would be an overkill for my needs. RAIDZ2 is already beyond our needs.
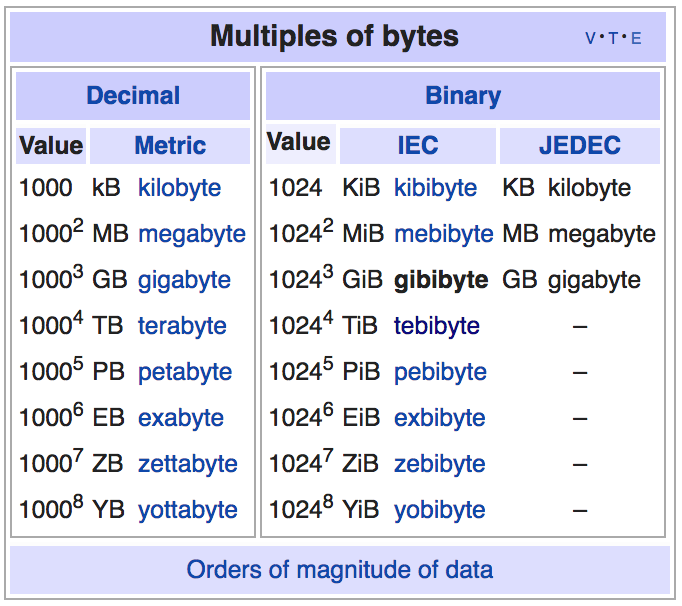
Raw storage (plain disks without any RAID) = 10 TB X 120 = 1.2 PB or 1091.4 TiB. As per SI system, Gigabyte(GB) is 1000000000 bytes or 109 bytes. However, per binary prefix system, Gibibyte(GiB) is 1073741824 bytes or 230 bytes. Harddrive manufacturers use GB & TB, but standard unix tools like du and df gives out numbers in KiB, GiB and TiB. So, I’ll stick to this convention.
| Number of vdevs | Disks per vdev | Spare disks | Num parity disks(2 per vdev) | Effective storage ratio | Usable ZFS storage |
|---|---|---|---|---|---|
| 9 | 13 | 3 | 18 | (120 - 3 spares - 18 parity disks) / 120 = 82.5% | 82.5% of 1091.4 TiB = 900.3 TiB |
| 14 | 8 | 8 | 28 | (120 - 8 spares - 28 parity disks) / 120 =70% | 70% of 1091.4 TiB = 763.7 TiB |
| 11 | 10 | 4 | 22 | (110 - 22 parity disks) / 110 =80% | 80% of 1000.45 TiB = 800 TiB |
| 1 | 6 | 4 | 2 | (6 - 2 parity disks) / 6 =67% | 67% of 54.5 TiB = 36.5 TiB |
| 14 | NA | 4 | 24 | (120 - 4 spares - 24 parity disks) / 120 =76.6% | 76.6% of 1091.4 TiB = 836 TiB |
Each of the three above choice balances a tradeoff between storage capacity, failure tolerance, and performance. I chose to go with the third choice, which is to build two separate pools - one for the data, and other for backing up our infrastructure servers(DNS, FreeIPA, Firewall etc). The data zpool (sec_stor) will have 10 disks per vdev and can tolerate a simultaneous failure of two disks within a vdev(and failure of upto 24 disks if they are distributed as two failures per vdev). The hot spares are expected to kick in the moment even one of them fails, so it is sufficient to keep the data safe.
ashift and a boat load of luck #
(updated information after feedback from Reddit r/zfs by Jim Salter - @jrssnet and u/fengshui)
What is ashift? Here is a snip from open-zfs wiki:
vdevs contain an internal property called ashift, which stands for alignment shift. It is set at vdev creation and it is immutable. It is calculated as the maximum base 2 logarithm of the physical sector size of any child vdev and it alters the disk format such that writes are always done according to it. This makes 2ashift the smallest possible IO on a vdev.
Configuring ashift correctly is important because partial sector writes incur a penalty where the sector must be read into a buffer before it can be written. ZFS makes the implicit assumption that the sector size reported by drives is correct and calculates ashift based on that.
In an ideal world, ZFS making an automatic choice based on what the disk declares about itself would be sweet. But, the world is not ideal!. You see, Some operating systems, such as Windows XP, were written under the assumption that sector sizes are 512 bytes and will not function when drives report a different sector size. So, instead of not supporting those old operating systems for the newest drives, the disk manufacturers sometimes decide to make the disk lie about its sector size. For example, in Jim’s case, a Kingston A400 SSD was advertizing its sector size as 512 bytes, when its actual sector was 8K. The performance cost of this idiocy is anecdotally orders of magnitude high.
Having learnt all of this information on Reddit after I deployed the backup server, I franctically tried to find out what ZFS was doing in my case.
I found the spec sheet for the HGST NAS 10TB SAS drives I used. It claims the disks are “Sector Size (Variable, Bytes/sector) 4Kn: 4096 512e: 512”. So, at the least these drives support 4K sector sizes.
First from sysctl, about what ZFS is reporting as ashift..
root@delorean:/sec_stor/backup/fiotest/fio-master # sysctl -a|grep ashift
vfs.zfs.min_auto_ashift: 9
vfs.zfs.max_auto_ashift: 13
This doesnt quite help, as the min_auto_ashift is still 9, which means that it is possible for ZFS to be using 29=512 bytes as sector size. But, it does give a breather that the max was above what I desire - 12.
So, I ran zdb to find out what ZFS reports as its running configuration.
root@delorean:/sec\_stor/backup/fiotest/fio-master # zdb | grep ashift
ashift: 12
ashift: 12
ashift: 12
ashift: 12
ashift: 12
ashift: 12
ashift: 12
ashift: 12
ashift: 12
ashift: 12
ashift: 12
ashift: 12

Whooof! All 12 of my vdevs are reporting a ashift of 12. Which means that they correctly identified the disks as with 4K sector sizes. I didnt make a mistake with a immutable config parameter purely by luck.
Okay. on with the original flow of the blog post…
Making ZFS happen #
It’s time to turn our design choices into actual configuration. As is the norm with FreeBSD, all disks are listed at /dev/da*
Create a zpool named sec_stor, and add the first vdev and our 4 hot spares. Then add the rest of the VDEVs.
> zpool create sec_stor raidz2 /dev/da0 /dev/da1 /dev/da2 /dev/da3 /dev/da4 /dev/da5 /dev/da6 /dev/da7 /dev/da8 /dev/da9 spare /dev/da110 /dev/da111 /dev/da112 /dev/da113
> zpool add sec_stor raidz2 /dev/da10 /dev/da11 /dev/da12 /dev/da13 /dev/da14 /dev/da15 /dev/da16 /dev/da17 /dev/da18 /dev/da19
> zpool add sec_stor raidz2 /dev/da20 /dev/da21 /dev/da22 /dev/da23 /dev/da24 /dev/da25 /dev/da26 /dev/da27 /dev/da28 /dev/da29
> zpool add sec_stor raidz2 /dev/da30 /dev/da31 /dev/da32 /dev/da33 /dev/da34 /dev/da35 /dev/da36 /dev/da37 /dev/da38 /dev/da39
> zpool add sec_stor raidz2 /dev/da40 /dev/da41 /dev/da42 /dev/da43 /dev/da44 /dev/da45 /dev/da46 /dev/da47 /dev/da48 /dev/da49
> zpool add sec_stor raidz2 /dev/da50 /dev/da51 /dev/da52 /dev/da53 /dev/da54 /dev/da55 /dev/da56 /dev/da57 /dev/da58 /dev/da59
> zpool add sec_stor raidz2 /dev/da60 /dev/da61 /dev/da62 /dev/da63 /dev/da64 /dev/da65 /dev/da66 /dev/da67 /dev/da68 /dev/da69
> zpool add sec_stor raidz2 /dev/da70 /dev/da71 /dev/da72 /dev/da73 /dev/da74 /dev/da75 /dev/da76 /dev/da77 /dev/da78 /dev/da79
> zpool add sec_stor raidz2 /dev/da80 /dev/da81 /dev/da82 /dev/da83 /dev/da84 /dev/da85 /dev/da86 /dev/da87 /dev/da88 /dev/da89
> zpool add sec_stor raidz2 /dev/da90 /dev/da91 /dev/da92 /dev/da93 /dev/da94 /dev/da95 /dev/da96 /dev/da97 /dev/da98 /dev/da99
> zpool add sec_stor raidz2 /dev/da100 /dev/da101 /dev/da102 /dev/da103 /dev/da104 /dev/da105 /dev/da106 /dev/da107 /dev/da108 /dev/da109
Verify that the zpool is what we expect it to be and that all devices are online.
root@delorean:~ # zpool status
pool: sec_stor
state: ONLINE
scan: none requested
config:
NAME STATE READ WRITE CKSUM
sec_stor ONLINE 0 0 0
raidz2-0 ONLINE 0 0 0
da0 ONLINE 0 0 0
da1 ONLINE 0 0 0
da2 ONLINE 0 0 0
da3 ONLINE 0 0 0
da4 ONLINE 0 0 0
da5 ONLINE 0 0 0
da6 ONLINE 0 0 0
da7 ONLINE 0 0 0
da8 ONLINE 0 0 0
da9 ONLINE 0 0 0
raidz2-1 ONLINE 0 0 0
da10 ONLINE 0 0 0
da11 ONLINE 0 0 0
da12 ONLINE 0 0 0
da13 ONLINE 0 0 0
da14 ONLINE 0 0 0
da15 ONLINE 0 0 0
da16 ONLINE 0 0 0
da17 ONLINE 0 0 0
da18 ONLINE 0 0 0
da19 ONLINE 0 0 0
raidz2-2 ONLINE 0 0 0
da20 ONLINE 0 0 0
da21 ONLINE 0 0 0
da22 ONLINE 0 0 0
da23 ONLINE 0 0 0
da24 ONLINE 0 0 0
da25 ONLINE 0 0 0
da26 ONLINE 0 0 0
da27 ONLINE 0 0 0
da28 ONLINE 0 0 0
da29 ONLINE 0 0 0
~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ trimmed for brevity.
raidz2-10 ONLINE 0 0 0
da100 ONLINE 0 0 0
da101 ONLINE 0 0 0
da102 ONLINE 0 0 0
da103 ONLINE 0 0 0
da104 ONLINE 0 0 0
da105 ONLINE 0 0 0
da106 ONLINE 0 0 0
da107 ONLINE 0 0 0
da108 ONLINE 0 0 0
da109 ONLINE 0 0 0
spares
da110 AVAIL
da111 AVAIL
da112 AVAIL
da113 AVAIL
errors: No known data errors
Create the second zpool
zpool create config_stor raidz2 /dev/da114 /dev/da115 /dev/da116 /dev/da117 /dev/da118
Lets see how much storage we built on this server.
root@delorean:~ # df -h
Filesystem Size Used Avail Capacity Mounted on
/dev/ada0p2 111G 1.8G 100G 2% /
devfs 1.0K 1.0K 0B 100% /dev
sec_stor 735T 201K 735T 0% /sec_stor
config_stor 26T 157K 26T 0% /config_stor
The curious case of missing 65TiB ?! #
According to the table earlier, I was supposed to have 800 TiB of usable ZFS storage. I see only 735 TiB. Where did the 65 TiB go?
My understanding was that the choice RAIDZ2 means that I’d lose 2 disks worth of storage space for parity as overhead. But, I was wrong. If you take reservations for parity and padding into account, and add in an extra 2.3% of slop space allocation, it explains the missing 65 TiB of storage capacity. Read through the Reddit post here to see the discussion.
You can use the calculator here to make more accurate capacity estimations than I did above.
For ZFS to make use of this storage we made available, we need to create a ZFS “dataset” on top of this. A zfs dataset is synonymous to a filesystem. Before we get to it, we need to think about a couple of ZFS storage efficiency features: Compression and Deduplication.
Storage efficiency: (Compression and Deduplication) #
Compression: (Source: FreeBSD docs) ZFS provides transparent compression. Compressing data at the block level as it is written not only saves space, but can also increase disk throughput. If data is compressed by 25%, but the compressed data is written to the disk at the same rate as the uncompressed version, resulting in an effective write speed of 125%. Compression can also be a great alternative to Deduplication because it does not require additional memory.
ZFS offers several different compression algorithms, each with different trade-offs. The biggest advantage to LZ4 is the early abort feature. If LZ4 does not achieve at least 12.5% compression in the first part of the data, the block is written uncompressed to avoid wasting CPU cycles trying to compress data that is either already compressed or uncompressible.
Deduplication: When enabled, deduplication uses the checksum of each block to detect duplicate blocks. However, be warned: deduplication requires an extremely large amount of memory, and most of the space savings can be had without the extra cost by enabling compression instead.
Having chosen LZ4 compression, we decided that the cost of dedupe in terms of memory requirements is not worth the effort in our usecase.
ZFS datasets #
With choice of compression already made, create ZFS datasets using:
zfs create -o compress=lz4 -o snapdir=visible /sec_stor/backup
zfs create -o compress=lz4 -o snapdir=visible config_stor/backup
Hot spares #
ZFS allows devices to be associated with pools as “hot spares”. These devices are not actively used in the pool, but when an active device fails, it is automatically replaced by a hot spare. This feature requires a userland helper. FreeBSD provides zfsd(8) for this purpose. It must be manually enabled by adding zfsd_enable=“YES” to /etc/rc.conf. With choice of compression already made, create ZFS datasets using:
echo 'zfsd_enable=“YES”' >> /etc/rc.conf
ZFS snapshots (on time) #
A key requirement in our solution is snapshots. A snapshot provides a read-only, point-in-time copy of the dataset. In a Copy-On-Write(COW) filesystem such as ZFS, snapshots come with very little cost because they are essentially nothing more than a point of duplication of blocks. Having regular scheduled snapshots, enables an user/administrator to recover deleted files from back in time saving enormous time & effort of restoring files from tape archives. In our specific usecase, it is not very uncommon for a user to request restoration of a research dataset that was intentionally deleted say 6 months ago. Instead of walking over to the archive room, finding the appropriate tapes, loading them into the robot, dealing with NetBackup, and patiently wait while it restores the dataset, I can just do
cd location/deleted/data
cp -R .zfs/snapshot/2018-06-10_13.00.00--30d/* .
echo "Sysadmin is happy!"
We already installed a package - zfsnap earlier in the setup. zfsnap is a utility that helps with creation and deletion of snapshots. A simple way to create a manual snapshot is possible without installing zfsnap..
zfs snapshot -r mypool@my_recursive_snapshot
But, we installed zfsnap for convenience. As a quick example, here is a one shot command to create a snapshot with a retention period of 10 years:
/usr/local/sbin/zfSnap -a 10y -r sec_stor/backup
As a backup server, I want this system to have a schedule of snapshots so that data can be recovered back in time, with varying levels of granularity. Here is what I came up with in our cron schedule for our needs.
snip from /etc/crontab :
# Run ZFS snapshot daily at 1 PM with retention period of 30 days
0 13 * * * root /usr/local/sbin/zfSnap -a 30d -r sec_stor/backup
# Run ZFS snapshot monthly at 2 PM on the first day of the month with retention period of 1 year
0 14 1 * * root /usr/local/sbin/zfSnap -a 1y -r sec_stor/backup
# Run ZFS snapshot yearly at 3 PM on 6th January every year with retention period of 10 years
0 15 6 * * root /usr/local/sbin/zfSnap -a 10y -r sec_stor/backup
# Run deletion of older stale snapshots at 4 PM on first day of every month
0 16 1 * * root /usr/local/sbin/zfSnap -d sec_stor/backup
This way, I get daily snapshots for 30 days, monthly snapshots for a year, yearly snapshots for 10 years. This will be communicated to the users in advance, so that they what to expect in terms of recovery from backups.
The last cron job is to clear out older snapshots that expire. For example, a daily snaphot from 35 days ago.
To give you an idea, here is the state of the server after a few months in operation:
$ zfs list -t all
NAME USED AVAIL REFER MOUNTPOINT
config_stor 1.16M 25.9T 156K /config_stor
config_stor/backup 156K 25.9T 156K /config_stor/backup
sec_stor 161T 574T 201K /sec_stor
sec_stor/backup 161T 574T 140T /sec_stor/backup
sec_stor/backup@2018-06-30_13.00.00--30d 6.46G - 133T -
sec_stor/backup@2018-07-01_13.00.00--30d 0 - 134T -
sec_stor/backup@2018-07-01_14.00.00--1y 0 - 134T -
sec_stor/backup@2018-07-01_16.00.00--1m 0 - 134T -
sec_stor/backup@2018-07-02_13.00.00--30d 3.52G - 134T -
sec_stor/backup@2018-07-03_13.00.00--30d 3.52G - 134T -
~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ trimmed for brevity.
Another view of the system after a few months of operation, to see how compression is working out for us.
$ zfs get used,compressratio,compression,logicalused sec_stor/backup
NAME PROPERTY VALUE SOURCE
sec_stor/backup used 161T -
sec_stor/backup compressratio 1.42x -
sec_stor/backup compression lz4 local
sec_stor/backup logicalused 224T -
1.42x is excellent. Basically, the sytem uses only 161T to store data that is 224T in size. Cool.
Scrub performance #
Having disks as big as 10TB, and many of them(even 10) could be a lot of work to scrub/rebuild. I’m not directly concerned about the degraded performance during a long scrub/rebuild, but I’m concerned that during the long scrub time, the VDEV will be vulnerable (with tolerance of only 1 additional disk failure). I read from a ZFS tuning guide that the following will help in this case, “If you’re getting horrible performance during a scrub or resilver, the following sysctls can be set:”
cat <<EOF >> /etc/sysctl.conf
vfs.zfs.scrub_delay=0
vfs.zfs.top_maxinflight=128
vfs.zfs.resilver_min_time_ms=5000
vfs.zfs.resilver_delay=0
EOF
This basically tells ZFS to ignore user side performance and get the scrub done. This will impact your user facing performance, but this being a backup server, we can safely play with these toggles. This change above is pre-mature optimization and is often considered evil to do such a thing. But, since availability is not critical in my use-case, I felt okay doing such a thing ¯\_(ツ)_/¯
Performance #
As stated earlier, performance was not a major goal for this setup. However, we’ll be missing out on fun if we didnt see some numbers while the system is pushed harder. I tested the write performance of this server with 0%, 50% & 100% compressible data. I detailed my notes on how I went about setting up and viewing results on a follow-up post here.
Essential zfs commands #
For quick reference, here are some zfs related commands I run on the server from time to time to check on the status.
# List the state of zpool
> zpool list
# Show status of individual disks in the zpool
> zpool status
# Show ZFS dataset(filesystem) stats
> zfs list
# Show percentage savings from compression
> zfs get used,compressratio,compression,logicalused <dataset name>
# List all available snapshots in the system
> zfs list -t filesystem,snapshot
# Watch read/write bandwidth in real time for an entire zpool
> zpool iostat -Td -v 1 10
# Watch per second R/W bandwidth util on zpool in a terse way
> zpool iostat <pool name> 1
# Watch disk util for all disks in real time
> systat -iostat -numbers -- 1
# A one stop command to get all ZFS related stats: https://www.freshports.org/sysutils/zfs-stats
# Install and run it using:
> pkg install zfs-stats
> zfs-stats -a
# Get configuration information at zpool level
> zpool get <pool name>
# Get configuration information at zfs level
> zfs get all <dataset name>
References: #
$ Book - FreeBSD Mastery by Michael W. Lucas
Calomel.org - ZFS health check
Reddit discussion on zpool choices
Reddit discussion on ZFS configuration